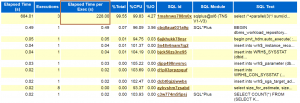
در گزارش AWR و همچنین ویوهایی نظیر V$SQLه، elapsed_timeای که برای parallel queryها نمایش داده می شود، جمع بین زمان سپری شدهquery coordinator و parallel query slaveها می باشد از این جهت، نباید این عدد را با elapsed_time واقعی پرس و جو اشتباه گرفت.
مثال زیر را ببینید:
SQL> select /*+parallel(3)*/ sum(id),sum(code),avg(count) from usef.myview;
SUM(ID) SUM(CODE) AVG(COUNT)
———- ———- ———-
713031680 3548381184 68.1508522
Elapsed: 00:01:18.89
SQL> /
SUM(ID) SUM(CODE) AVG(COUNT)
———- ———- ———-
713031680 3548381184 68.1508522
SQL> /
Elapsed: 00:01:17.08
SQL> /
SUM(ID) SUM(CODE) AVG(COUNT)
———- ———- ———-
713031680 3548381184 68.1508522
Elapsed: 00:01:17.94
پس از اجرای دستورات فوق، در گزارش AWR خواهیم دید که Elapsed Time برای query اجرا شده برابر با 228 ثانیه می باشد در صورتی که این query در مدت زمان80 ثانیه(حدودا) اجرا شده است: