اوراکل در کنار قابلیتهای متعددی که در هر نسخه ارائه می کند، بعضی از قابلیتهای قبلی را deprecate و یا desupport می کند. deprecate به این معنی که آن قابلیت دیگر بهبودی نخواهد داشت و از نسخه های بعدی desupport می شود و desupport هم به این معنی که اگر باگی داشته باشد، رفع باگی توسط اوراکل انجام نمی شود و بعضا به طور کامل امکان استفاده از آن از بین می رود.
در ادامه این متن تعدادی از قابلیتهای شناخته شده ای که اوراکل از نسخه 23ai دیگر از آنها پشتیبانی نمی کند، را مرور می کنیم.
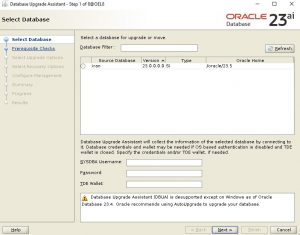
ابزار Database Upgrade Assistant (DBUA) و ارتقای دستی: از نسخه 23ai اوراکل توصیه می کند از AutoUpgrade برای ارتقاء نسخه دیتابیس استفاده کنیم و از این نسخه، ابزار dbua را در محیط لینوکس پشتیبانی نمی کند همچنین اسکریپتهای ارتقاء دستی نظیر catupgrd, dbupgrade, catctl در این نسخه پشتیبانی نمی شوند البته استفاده از ابزار DBUA در محیط ویندوز کماکان امکان پذیر است.