در این متن مراحل نصب اوراکل لینوکس نسخه 8.4 را توضیح خواهیم داد.
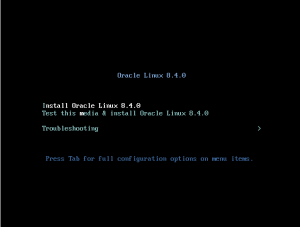
1.در گام نخست، گزینه Install Oracle Linux 8.4.0 را انتخاب می کنیم:
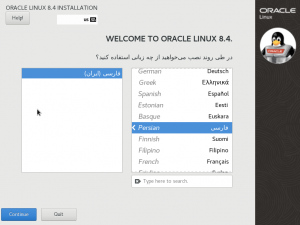
2.در قدم بعدی زبان مورد نظر در طول نصب سیستم عامل را انتخاب می کنیم:
……….آموزش، مشاوره و پشتیبانی……….
در این متن مراحل نصب اوراکل لینوکس نسخه 8.4 را توضیح خواهیم داد.
1.در گام نخست، گزینه Install Oracle Linux 8.4.0 را انتخاب می کنیم:
2.در قدم بعدی زبان مورد نظر در طول نصب سیستم عامل را انتخاب می کنیم:
یکی از روش های بهبود پرفورمنس در دیتابیس اوراکل استفاده از قابلیت REBUILD کردن ایندکس ها است. REBUILD کردن ایندکس هایی که با روشی مناسب انتخاب می شوند می تواند پرفورمنس دیتابیس را به طور قابل ملاحظه ای بهبود دهد. البته عملیات آنالیز و REBUILD ایندکس زمانبر بوده و سربار ایجاد می کند. در این متن REBUILD ایندکس ها و روش استفاده مناسب از آن توضیح داده می شود.
جداول از نوع Immutable که اصطلاحا insert-only table هم نامیده می شوند، برای محافظت اطلاعات جدول از هرگونه دستکاری کاربرد دارند. در این نوع از جداول، درج اطلاعات جدید امکان پذیر است اما قابلیت بروزرسانی و اصلاح وجود ندارد و حداقل برای مدت زمان مشخصی، از حذف جدول و یا حذف اطلاعات آن ممانعت خواهند شد. این دسته از جداول در اوراکل 21.3 ارائه شدند و در نسخه 19.11 هم قابل استفاده هستند.
جداول Immutable را می توان از طریق دستور CREATE IMMUTABLE TABLE ایجاد کرد همچنین در زمان ایجاد این نوع از جداول، می توان در مورد حذف جدول(DROP) و حذف رکوردهای جدول(DELETE) سیاستهایی را اعمال کرد.
پارامتر DB_FILE_MULTIBLOCK_READ_COUNT تعداد بلاک هایی که می توانند در هر مرحله از FULL TABLE SCAN با عملیات I/O از دیسک به حافظه منتقل شوند را مشخص می کند البته حداکثر تعداد MULTI BLOCK در زمان اجرا وابسته به پشتیبانی سیستم است. در این متن ویژگی ها و نحوه برخورد اوراکل با این پارامتر را توضیح می دهیم و عملیات خواندن همزمان بلاک ها با یک مثال اجرایی نمایش داده می شود.
اگر بعد از ارتقا نسخه Grid Infrastructure به 19c تصمیم گرفتید آن را دوباره به نسخه قبل برگردانید، پیشنهاد می کنیم متن پیش رو که در ان مراحل Downgrade نسخه Grid از 19.11 به 18.5 توضیح داده شده را مطالعه بفرمایید.
عملیات Downgrade در کلاستری با دو نود انجام شده که دستورات زیر اطلاعاتی را در مورد نسخه جاری Grid ارائه می کنند:
[grid@RAC2 ~]$ crsctl query crs activeversion
Oracle Clusterware active version on the cluster is [19.0.0.0.0]
SQL> select BANNER_FULL from v$version;
Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 – Production
Version 19.11.0.0.0
عملیات Downgrade را در طی 7 مرحله انجام خواهیم داد.
در دیتابیس اوراکل، OPTIMIZER برای هر دستور SQL مسیرهای دسترسی مختلف به جدول ها را تعیین کرده و با یکدیگر مقایسه می کند تا بهینه ترین مسیر برای EXECUTION PLAN را انتخاب کند. این مقایسه بر اساس آمارهای جمع آوری شده از ایندکس ها و جدول های دیتابیس انجام می شود.
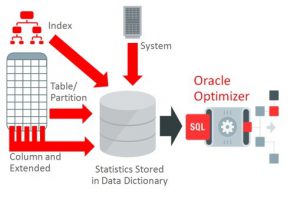
برای هر EXECUTION PLAN مسیر دسترسی نهایی به داده ها با استفاده از عمل SCAN مشخص می شود. در این متن انواع مختلف SCANهای OPTIMIZER توضیح داده می شوند.
همانطور که می دانید، IOT Deviceها به طور پیوسته جریانی از داده را به سمت دیتابیس هدایت می کنند به طوری که درج این داده ها در دیتابیس رابطه ای می تواند با چالشهای پرفورمنسی همراه باشد.
در اوراکل نسخه 19c ، راهکاری برای حل این مسئله پرفورمنسی ارائه شد که مطابق با آن، این دسته از دیتا ابتدأَ در حافظه ثبت شده و در نهایت به صورت دسته ای به دیسک منتقل می شوند. این قابلیت جدید، Memoptimized Rowstore Fast Ingest نام دارد.
البته به این ویژگی اصطلاحا deferred insert هم گفته می شود چرا که ابتدا دیتا در قسمتی از large pool ثبت می شود و بعد از گذشت مدت زمانی، به صورت خودکار توسط اوراکل به دیسک منتقل شده و در زمانی که دیتا در Large Pool قرار دارد، توسط sessionهای دیگر قابل رویت نخواهد بود.
ایندکس های بی استفاده سبب ایجاد سربار در عملیات DML می شوند و فضای دیتابیس را هدر می دهند. همانطور که در مطلب روشی برای شناسایی ایندکس های تکراری اشاره شد می توان تعداد موارد بکارگیری ایندکس ها توسط OPTIMIZER در بازه های زمانی گذشته را استخراج کرد و ایندکس های بی استفاده را حذف نمود. در این متن سه روش مختلف برای شناسایی ایندکس های بی استفاده را توضیح می دهیم.
بروزرسانی Materialized View(MV) به روش Out of Place ، قابلیت جدیدی بود که در اوراکل نسخه 12c ارائه شد، در این روش، در زمان بروزرسانی MV، به جای دستکاری جدول جاری MV، اوراکل جدول جدیدی را ایجاد می کند و حاصل اجرای متن MV را در این جدول درج خواهد کرد بعد از آنکه اطلاعات بروز شده به صورت کامل در جدول جدید درج شد، این جدول با جدول جاری MV جایگزین می شود.
با توجه به آنکه در مورد ویژگی Out Of Place Refresh قبلا مطلبی را ارائه کردیم از تکرار مجدد آن پرهیز کرده و در این مطلب به بررسی یکی مضرات پرفورمنسی این شیوه از بروزرسانی خواهیم پرداخت.
Out Of Place Refresh در کنار مزایایی که دارد ممکن در شرایطی برای دیتابیس سربار پرفورمنسی ایجاد کند. چرا که در این روش از بروزرسانی، با هر بار بروزرسانی MV، جدولی حذف و جدول جدیدی ایجاد خواهد شد و جدول جدید مشخصات مختص به خود را دارد(نظیر object_id و …) و برای دیتابیس یک object جدید محسوب می شود.
ایجاد جدول جدید سبب می شود تا فرمهای پارس شده همه پرس و جوهایی که به این MV رجوع کرده اند، نامعتبر شده و از حافظه خارج شوند و این پرس و جوها برای اجرای مجدد، باید یکبار دیگر پارس شوند.
همانطور که در مطلب ایندکس های ترکیبی اشاره شد می توان در کنار ایندکس های عادی، ایندکس های ترکیبی که ترتیب ستون های آنها از اهمیت زیادی برخوردار است ایجاد کرد تا QUERYهای مختلف بتوانند با سرعت بالاتر اجرا شوند.
از طرفی دیگر استفاده از ایندکس های زیاد سبب ایجاد سربار در عملیات DML می شود و فضای دیتابیس را هدر می رود. در این متن یک QUERY برای یافتن ایندکس هایی که ستون های تکراری دارند معرفی می شود.