زمان اجرای دو پرس و جوی زیر را با هم مقایسه کنید:
SQL> set timing on
پرس و جوی اول:
SQL> select /*+FULL(TBL1)*/ count(*) from tbl1;
COUNT(*)
———-
176000000
Elapsed: 00:00:02.33
……..آموزش، مشاوره و پشتیبانی…….
زمان اجرای دو پرس و جوی زیر را با هم مقایسه کنید:
SQL> set timing on
پرس و جوی اول:
SQL> select /*+FULL(TBL1)*/ count(*) from tbl1;
COUNT(*)
———-
176000000
Elapsed: 00:00:02.33
برای اعمال نظر در مورد execution plan پرس و جویی که اصلاح متن ان امکان پذیر نیست، می توان از sql profile کمک گرفت و از طریق ایجاد ان، هینتهایی را به این پرس و جو اعمال کرد. در ادامه همراه با یک مثال ساده، اثر استفاده از sql profile را بررسی خواهیم کرد.
در زمان انجام عملیات join بین دو جدول که یکی در بانک local و دیگری در بانک remote موجود است ، به طور پیش فرض اطلاعات جدول حاضر در بانک remote به بانک local فرستاده خواهد شد و سپس عملیات join انجام می شود.
حال اگر جدول حاضر در بانک remote، حجم بسیار بیشتری از جدول local داشته باشد، انجام عملیات join بسیار کند انجام خواهد شد.
برای این مورد مشخص، در صورتی که عملیات به صورت کامل در بانک remote انجام شوند و در نهایت نتیجه به بانک مبدا برگردد، سرعت انجام عملیات بهتر خواهد شد برای انجام این کار، می توان از هینتی به نام DRIVING_SITE استفاده کرد.
با کمک این ویژگی می توان بر روی یک ستون، انواع مختلفی از ایندکسها نظیر Bitmap، B-Tree، Reverse و … را ایجاد نمود که البته از بین این ایندکسها، صرفا یکی از انها می تواند در حالت visible قرار داشته باشد و مابقی ایندکسها، باید در حالت invisible قرار بگیرند.
(بیشتر…)در دنیای واقعی کارهای بسیاری وجود دارند که اساسا امکان انجام آنها به صورت سریالی به سختی قابل انجام است و به ناچار نیاز است که این کارها به صورت موازی و همروند اجرا شوند به صورت مثال، فرض کنید نیاز است تا در کشوری همانند چین، سرشماری به صورت دستی انجام بگیرد انجام این عمل توسط یک فرد شاید مضحک و غیرعملی بنظر برسد و ممکن است فرد تا پایان سرشماری، از دنیا برود!!! به همین دلیل نیاز است تا سازمانی برای انجام این کار ایجاد شود و نیروهایی را به استخدام خود در بیاورد تا بتواند با تقسیم کار بین آنها، این عمل را با سرعت بیشتری به انجام برساند.
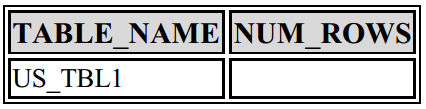
در نسخه 11g، با اجرای دستور create table as، آماری از جدول ایجاد شده، ثبت نمی شود:
create table us_tbl1 as select * from dba_source;
SELECT table_name,num_rows FROM dba_tables WHERE table_name = ‘US_TBL1’;
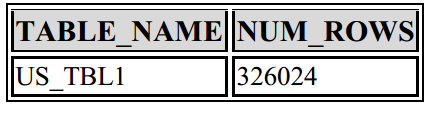
حال اگر همین دستور در نسخه 12c اجرا شود، نتیجه چیزی دیگری خواهد بود(البته استثناهایی هم در این زمینه وجود دارد):
create table us_tbl1 as select * from dba_source;
SELECT table_name,num_rows FROM dba_tables WHERE table_name = ‘US_TBL1’;
همچنین می توان با هینت NO_GATHER_OPTIMIZER_STATISTICS، از این قابلیت جدید، صرف نظر کرد:
create table us_tbl1 as select /*+ NO_GATHER_OPTIMIZER_STATISTICS */ * from dba_source ;
فرض کنید بلاکی توسط session شماره یک مورد دستیابی قرار گرفته و توسط آن در بافر pin شده است(هر بافر در هر لحظه تنها توسط یک session می تواند pin شود) و در همین حال session دیگری قصد دسترسی به آن بلاک را دارد در این صورت session دوم باید در انتظار بماند به این مدل از انتظار Buffer Busy Wait گفته می شود.
سه روش برای JOIN بین جداول وجود دارد:
Nested loop – Hash join – Sort merge join
در این متن، به بررسی این سه روش خواهیم پرداخت.
(بیشتر…)زمانی که یک دستور با چندین شرط join اجرا می شود، عمل join در هر لحظه تنها بین دو جدول آن دستور انجام خواهد شد به عبارت دیگر، عمل join یک عمل باینری می باشد و ترتیب انجام آن، می تواند به لحاظ پرفورمنسی، کارساز باشد.
برای تعیین ترتیب join بین جداول، باید حالات مختلفی توسط اوراکل بررسی شود که این کار می تواند وقت زیادی را از سیستم بگیرد برای جلوگیری از این اتلاف وقت، می توان ترتیب پیوند را با استفاده از هینت ORDERED تعیین کرد.
در قسمت زیر خواهیم دید که با کمک این هینت دریک دستور، ترتیب پیوندها بر اساس ترتیب جداول در عبارت from تعیین خواهند شد.
(بیشتر…)وقتی که اوراکل دستوری را اجرا می کند، سعی دارد تا فرم قابل اجرای دستور اجرا شده(که plan آن مشخص شده) را در library cache نگهدارد تا در صورت امکان، از آن استفاده مجدد کند حال اگر این فرم پارس شده برای دستور دیگری مورد استفاده قرار بگیرد می گویند یک soft parse انجام شده است و در صورتی که اوراکل مجبور شود یک فرم جدید قابل اجرا(که در library cache موجود نیست) برای دستور وارده بسازد، hard parse صورت گرفته است.