همانطور که می دانید، با انتقال بلاک یک جدول از دیسک به حافظه(بافرکش) و دسترسی کاربر به اطلاعات موجود در آن، این بلاک برای مدت زمانی در حافظه باقی خواهد ماند(البته در صورت امکان) تا در صورت نیاز به رجوع مجدد، لزومی به انجام physical read دوباره برای دستیابی به این اطلاعات نباشد. مکرر در مستندات اوراکلی خوانده ایم که مدیریت این caching در سطح بلاک(نه در سطح object) و با کمک الگوریتم (LRU(least recently used انجام می شود.
حال اگر نیاز باشد جدول نسبتا حجیمی(تقریبا به اندازه بافرکش)، ان هم صرفا برای یکبار دسترسی، از دیسک به حافظه منتقل شود، تکلیف بلاکهای حاضر در بافرکش چه خواهد شد؟!
انچه که به عنوان راهکار اول به ذهن متبادر می شود، انتقال بلاکهای این جدول به حافظه و جایگزین کردن آنها با دیگر بلاکهای موجود در buffer cache می باشد!
نقطه ضعف اساسی این راه حل، در بیرون راندن بلاکهایی خواهد بود که به کررات توسط کاربران مختلف به انها رجوع می شود.
از دیگر راه حلهایی که قبل از اوراکل 12c برای این مسئله وجود داشت، انجام direct path read بود طوری که بلاکهای این جدول حجیم، به جای انتقال از دیسک به sga، به محیط pga منتقل شوند البته این اتفاق سبب می شد تا کاربر دیگری به این بلاکها دسترسی نداشته باشد ولی در عوض، نقطه ضعف اساسی روش قبلی که بیرون راندن بلاکهای پراستفاده موجود در بافرکش بود، از بین می رفت(برای مطالعه مفصل تر در زمینه direct path read، به مطلب “بررسی انواع checkpoint” مراجعه کنید.)
از اوراکل 12c، روش دیگری برای حل این مسئله ارائه شد! در این روش می توان بافرکش را به دو قسمت تقسیم کرد و درصد مشخصی از اندازه بافرکش را برای جداول نسبتا حجیم در نظر گرفت به این ویژگی، Automatic Big Table Caching گفته می شود که در این متن به آن خواهیم پرداخت.
قبلا اشاره شد که برای مدیریت بلاکهای حاضر در buffer cache، از الگوریتم LRU در سطح block استفاده می شود با ارائه ویژگی Automatic Big Table Caching و تقسیم بافرکش به دو قسمت، مدیریت caching برای قسمت جدید، در سطح object و با کمک الگوریتم temperature انجام می شود. در این الگوریتم، با رجوع بیشتر به یک شی، temperature آن شی هم عدد بالاتری را نشان خواهد داد و در نتیجه، آن شی شانس بیشتری برای ماندن در قسمت Big Table Cache را دارا خواهد بود همچنین، شی ای که میزان دسترسی بالایی را دارد، اصطلاحا hotter object(در مقابل colder object) شناخته می شود و همیشه مبارزه ای بین hotter object و colder object در جریان خواهد بود.
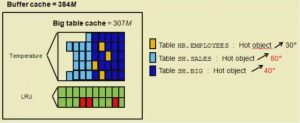
برای استفاده از این ویژگی، باید مقدار پارامتر DB_BIG_TABLE_CACHE_PERCENT_TARGET را به عددی غیر از صفر تنظیم نمود(از 1 تا 90) این عدد، درصد استفاده از بافرکش را برای Big Table Caching مشخص خواهد کرد.
این ویژگی در محیط کلاستر، تنها برای parallel query کاربرد دارد(parallel full scan) و برای پرس و جوهای سریالی، قابل استفاده نخواهد بود. همچنین برای استفاده از این ویژگی در محیط RAC، باید پارامتر PARALLEL_DEGREE_POLICY را به یکی از مقادیر AUTO و یا adaptive تنظیم کرد. در محیط single instance، محدودیتی از این نظر وجود ندارد و از serial query هم پشتیبانی خواهد شد.
در ادامه با سناریویی نشان خواهیم داد که چگونه با فعال کردن این ویژگی، بلاکهای مربوط به جداول بزرگ از دیسک به قسمت Big Table Caching منتقل خواهند شد. همچنین روشن خواهیم ساخت که چگونه این ویژگی، مانع از انجام عملیات direct path read خواهد شد.
در ابتدا با کمک دستورات زیر، وضیعت جاری sga و buffer cache را بررسی می کنیم:
SQL> show parameter sga_
NAME VALUE
———— ———–
sga_max_size 14G
sga_target 14G
SQL>select COMPONENT, CURRENT_SIZE/1024/1024 SIZE_MB from v$sga_dynamic_components where component = ‘DEFAULT buffer cache’;
| COMPONENT | SIZE_MB |
| DEFAULT buffer cache | 12576 |
همچنین مقادیر پارامترهایی که بر اساس انها، یک شی به عنوان Big Table به حساب خواهد امد را با کمک پرس و جوی زیر خواهیم دید:
SELECT ksppinm , ksppstvl, ksppdesc FROM x$ksppi x, x$ksppcv y WHERE x.indx = y.indx AND TRANSLATE(ksppinm,’_’,’#’) like ‘#%’ and ksppinm in(‘_db_block_buffers’,’_small_table_threshold’) ORDER BY ksppinm;
|
KSPPINM |
KSPPSTVL |
KSPPDESC |
| db_block_buffers_ | 1493901 | Number of database blocks cached in memory: hidden parameter |
| small_table_threshold_ | 29878 | lower threshold level of table size for direct reads |
بر اساس این پرس و جو، پارامتر مخفی small_table_threshold_ که به طور پیش فرض اندازه ای برابر با دو درصد از db_block_buffers_ را دارد، تعداد 29878 بلاک را نشان می دهد و جداولی که تعداد بلاک انها کمتر از این مقدار می باشد، small table تلقی خواهند شد.
در ادامه قصد فراخوانی دو جدول با حجمی برابر با 7G و 12G را داریم:
select bytes/1024/1024 “SIZE MB”,t.blocks from dba_segments s,dba_tables t where segment_name in(‘TBL_7G’,’TBL_12G’) and t.table_name=s.segment_name
| SIZE MB | BLOCKS |
| 7848 | 1003043 |
| 12368 | 1581038 |
بررسی خواهیم کرد که با غیرفعال بودن ویژگی ABTC، فراخوانی دو جدول به صورت direct path read انجام خواهد شد یا خیر؟
–db_big_table_cache_percent_target=0;
SQL> ALTER SESSION SET TRACEFILE_IDENTIFIER = ‘direct_path’;
Session altered.
SQL> ALTER SESSION SET events ‘10046 trace name context forever, level 12’;
Session altered.
SQL> select /*+full(tbl_12G)*/ count(*) from tbl_12G;
COUNT(*)
———-
36886082
با رجوع به فایل تریس، خواهیم دید که دسترسی به جدول، به صورت direct path انجام شده است:
WAIT #139933794320912: nam=‘direct path read’ ela= 733 file number=57 first dba=602592 block cnt=16 obj#=241090 tim=696635045961
WAIT #139933794320912: nam=‘direct path read’ ela= 6180 file number=57 first dba=602624 block cnt=16 obj#=241090 tim=696635052386
WAIT #139933794320912: nam=‘direct path read’ ela= 5382 file number=57 first dba=602656 block cnt=16 obj#=241090 tim=696635058018
STAT #139933794320912 id=2 cnt=36886082 pid=1 pos=1 obj=241090 op=‘TABLE ACCESS FULL TBL_12G (cr=1574358 pr=1572187 pw=0 str=1 time=63951372 us cost=347805 size=0 card=36377127)’
نکته: اگر حجم بالایی از بلاکهای یک Big Table در بافرکش موجود باشند(طبق یک قول، بالای 50 درصد)، از انجام عملیات direct path read برای خواندن این جدول صرف نظر خواهد شد.
حال قصد داریم تا با فعال کردن ویژگی ABTC، عملیات full table scan مربوط به جدول tbl_12g، با کمک Big Table Caching انجام شود. برای این کار، پارامتر db_big_table_cache_percent_target را به مقدار 90 تنظیم می کنیم:
SQL>alter system set db_big_table_cache_percent_target=90;
System altered
بعد از فعال کردن این ویژگی، جدول مورد نظر را فراخوانی می کنیم:
SQL> select /*+full(tbl_12G)*/ count(*) from tbl_12G;
COUNT(*)
———-
36886082
بعد از این فراخوانی، با کمک فایل تریس خواهیم دید که برای اجرای این دستور، دیگر از عملیات direct path read خبری نخواهد بود و در مقابل، db file scattered read که گواه بر خواندن بلاکهای جدول از دیسک به حافظه می باشد قابل مشاهده خواهد بود:
WAIT #140498515544256: nam=‘db file scattered read’ ela= 6154 file#=87 block#=3923353 blocks=128 obj#=241090 tim=697278062484
WAIT #140498515544256: nam=‘db file scattered read’ ela= 6539 file#=87 block#=3923481 blocks=128 obj#=241090 tim=697278070047
WAIT #140498515544256: nam=‘db file scattered read’ ela= 6450 file#=87 block#=3923609 blocks=128 obj#=241090 tim=697278077536
STAT #140674534754496 id=2 cnt=36886082 pid=1 pos=1 obj=241090 op=‘TABLE ACCESS FULL TBL_12G (cr=1572235 pr=1572342 pw=0 str=1 time=128994321 us cost=347805 size=0 card=36377127)’
همچنین استفاده از ویوهای مرتبط با ABTC، برای اثبات این مسئله، مفید می باشند که برای مانیتور کردن فضای Big Table Caching، می توان از دو ویوی v$bt_scan_cache و V$BT_SCAN_OBJ_TEMPS در این زمینه کمک گرفت:
SQL> select * from V$BT_SCAN_OBJ_TEMPS;
| TS# | DATAOBJ# | SIZE_IN_BLKS | TEMPERATURE | POLICY | CACHED_IN_MEM | CON_ID |
| 2 | 4196 | 744259 | 2000 | MEM_ONLY | 744259 | 0 |
| 2 | 4202 | 46178 | 1000 | MEM_ONLY | 46178 | 0 |
| 14 | 248100 | 1581038 | 1000 | MEM_PART | 597102 | 0 |
| 14 | 1281728 | 1003043 | 1000 | DISK | 0 | 0 |
در خروجی ویوی V$BT_SCAN_OBJ_TEMPS می توان اطلاعات اشیاهایی که در ناحیه Big Table Cache قرار دارند را مشاهده کرد. اطلاعاتی از قبیل:
#TS: شماره tablespaceای که شی در ان ذخیره شده است.
#DARAOBJ: شماره شی که از ویوی dba_objects بدست خواهد امد:
select l.object_name from dba_objects l where l.data_object_id=248100;
tbl_12G
SIZE_IN_BLKS : تعداد بلاکهای شی
TEMPERATURE: شماره TEMPERATURE که میزان اهمیت و همچنین درجه رجوع به شی را نشان می دهد.
POLICY: در صورتی که همه بلاکهای Big Table در Big Table Cache قرار گرفته باشد، این ستون، MEM_ONLY را نشان خواهد داد و اگر همه بلاکهای جدول، به حافظه منتقل نشده باشند و تعدادی از این بلاکها، در دیسک موجود باشند، عبارت MEM_PART قابل رویت می باشد و در نهایت، در صورتی که بلاکهای شی، هنوز به حافظه منتقل نشده باشند و یا از حافظه رانده شده باشند، عبارت DISK در این ستون قابل مشاهده می باشد.
CACHED_IN_MEM: چه تعداد از بلاکهای یک شی، در Big Table Cache قرار دارند؟
CON_ID: شماره container در محیط PDB
علاوه بر ویوی V$BT_SCAN_OBJ_TEMPS، ویوی دیگری به نام V$BT_SCAN_CACHE هم در این زمینه وجود دارد که اطلاعات بیشتری را در زمینه ارائه می دهد اطلاعاتی از قبیل تعداد اشیاهای حاضر در buffer cache، حداکثر اندازه Big Table cache نسبت به بافرکش، تعداد بافر تخصیص داده شده و ….
select BT_CACHE_TARGET, OBJECT_COUNT, MEMORY_BUF_ALLOC, MIN_CACHED_TEMP from v$bt_scan_cache;
| BT_CACHE_TARGET | OBJECT_COUNT | MEMORY_BUF_ALLOC | MIN_CACHED_TEMP |
| 90 | 5 | 1387849 | 1000 |
در انتهای این متن، قصد داریم با ارائه یک مثال ساده، وضیعت عدد TEMPERATURE را بعد از هر بار اجرای دستورات، دنبال کنیم. برای این کار، دو دستور زیر را که برای اجرای انها، از این ویژگی(ABTC) استفاده می شود، به کررات در بانک اجرا کرده ایم:
select * from tbl_7G; => DATAOBJ# =1281728
select * from tbl_12G; => DATAOBJ# =248100
وضیعت فعلی ABTC به صورت زیر می باشد:
SQL>select * from V$BT_SCAN_OBJ_TEMPS;
| TS# | DATAOBJ# | SIZE_IN_BLKS | TEMPERATURE | POLICY | CACHED_IN_MEM |
| 14 | 1281728 | 1003043 | 36000 | MEM_PART | 30966 |
| 14 | 248100 | 1581038 | 34000 | DISK | 0 |
در همین وضیعت، جدول tbl_12G که درجه حرارات ان برابر با 34000 می باشد را یکبار اجرا می کنیم و خروجی دستور قبلی را مشاهده می کنیم:
SQL> select /*+full(tbl_12G)*/ count(*) from tbl_12G; => DATAOBJ# =248100
SQL> select * from V$BT_SCAN_OBJ_TEMPS;
| TS# | DATAOBJ# | SIZE_IN_BLKS | TEMPERATURE | POLICY | CACHED_IN_MEM |
| 14 | 1281728 | 1003043 | 36000 | MEM_PART | 30966 |
| 14 | 248100 | 1581038 | 35000 | DISK | 0 |
همانطور که می بینید، کماکان جدول شماره 1281728 که همان tbl_7g می باشد، در Big Table Cache حاضر می باشد و به tbl_12g، اجازه حضور در این قسمت از حافظه داده نشد. فایل تریس مربوط به این دستور هم این موضوع را نشان می دهد:
WAIT #139857066041304: nam=‘direct path read’ ela= 8855 file number=55 first dba=1130368 block cnt=16 obj#=241090 tim=757792593417
WAIT #139857066041304: nam=‘direct path read’ ela= 5786 file number=55 first dba=1130384 block cnt=16 obj#=241090 tim=757792599367
WAIT #139857066041304: nam=‘direct path read’ ela= 5902 file number=55 first dba=1130400 block cnt=16 obj#=241090 tim=757792605443
مجددا این دستور را اجرا می کنیم:
SQL> select /*+full(tbl_12G)*/ count(*) from tbl_12G; => DATAOBJ# =248100
| TS# | DATAOBJ# | SIZE_IN_BLKS | TEMPERATURE | POLICY | CACHED_IN_MEM | CON_ID |
| 14 | 1281728 | 1003043 | 36000 | MEM_PART | 30966 | 0 |
| 14 | 248100 | 1581038 | 36000 | DISK | 0 | 0 |
کماکان به جدول tbl_12g اجازه ورود به این قسمت از حافظه داده نشده است و عدد TEMPERATURE، از 35هزار به 36هزار رسیده است پس دو جدول درجه حرارت یکسانی دارند. مجددا این دستور را اجرا می کنیم:
SQL> select /*+full(tbl_12G)*/ count(*) from tbl_12G; => DATAOBJ# =248100
| TS# | DATAOBJ# | SIZE_IN_BLKS | TEMPERATURE | POLICY | CACHED_IN_MEM | CON_ID |
| 14 | 248100 | 1581038 | 37000 | MEM_PART | 32394 | 0 |
| 14 | 1281728 | 1003043 | 36000 | DISK | 0 | 0 |
با اجرای مجدد این دستور، سرانجام مقدار TEMPERATURE مربوط به جدول tbl_12g بر جدول tbl_7g غلبه کرد و سبب خروج بلاکهای جدول tbl_7g به بیرون از حافظه شد ولی کماکان عدد TEMPERATURE مربوط به این جدول، از بین نرفته است تا در صورت دسترسی های مکرر به tbl_7g، این جدول به حافظه اورده شود. همچنین فایل تریس مربوط به این دستور نشان می دهد که خبری از direct path read در هنگام دسترسی به جدول tbl_12g نبوده است:
WAIT #139857066041304: nam=‘db file scattered read’ ela= 8405 file#=46 block#=1984277 blocks=128 obj#=241090 tim=758388722674
WAIT #139857066041304: nam=‘db file scattered read’ ela= 10428 file#=46 block#=1984405 blocks=128 obj#=241090 tim=758388734179
WAIT #139857066041304: nam=‘db file scattered read’ ela= 9239 file#=46 block#=1984533 blocks=128 obj#=241090 tim=758388744565
قبلا اشاره شد که استفاده از این ویژگی در محیط rac، تنها برای پرس و جوهای همروند کاربرد دارد. در ادامه با یک مثال در این زمینه، بحث را خاتمه خواهیم داد:
SQL>alter system set db_big_table_cache_percent_target=90;
System altered.
SQL>alter system set parallel_degree_policy=auto;
System altered.
SQL>select /*+parallel(p)*/ count(*) from sys.AUD$ p;
SQL>select * from v$bt_scan_obj_temps;
| TS# | DATAOBJ# | SIZE_IN_BLKS | TEMPERATURE | POLICY | CACHED_IN_MEM | CON_ID |
| 0 | 559 | 137579 | 1000 | MEM_ONLY | 137579 | 0 |
SQL>select l.OBJECT_NAME from dba_objects l where l.DATA_OBJECT_ID=559;
AUD$
وحید یوسف زاده
ارائه خدمات مشاوره ، پشتیبانی و نصب و راه اندازی پایگاه داده اوراکل در سراسر کشور...................... تلفن: 09128110897 ایمیل:vahidusefzadeh@gmail.com
Comment (1)