در دیتابیس اوراکل انواع مختلفی از ایندکسها وجود دارند که به منظور بهبود کارایی دیتابیس استفاده می شوند ولی هر کدام از آنها دارای کاربرد و ساختار متفاوت است.
ایندکس ها عناصر اختیاری برای جداول و کلاسترها هستند که می توانند با فراهم نمودن مسیرهای جدید دسترسی به داده ها سبب افزایش سرعت اجرای دستوات SQL شوند. در این متن ایندکس های از نوع FUNCTION BASED و روش استفاده مناسب از آنها را توضیح می دهیم.
ایندکس FUNCTION BASED چیست؟
فرض کنید یک ایندکس به نام ind_nam برای ستون nam تعریف می شود:
Create index ind_nam on tbl1(nam);
بنابراین OPTIMIZER در اجرای QUERY زیر از ایندکس ind_nam استفاده می کند:
Select * from tbl1 WHERE nam=’milad’;
اما زمانی که در یک QUERY، توابع یا عملیات خاص روی ستون nam اعمال شود از ایندکس ind_nam استفاده نخواهد شد:
Select * from tbl1 WHERE upper(nam)=’MILAD’;
در این مواقع اگر برای ستون nam ایندکس از نوع function based ساخته شود OPTIMIZER از آن ایندکس استفاده خواهد کرد و سرعت اجرای دستور افزایش می یابد:
Drop index ind_nam;
Create index ind_FUNC_BASED_nam on tbl1(upper(nam));
ایندکس ind_FUNC_BASED_nam شامل تمام نام های ستون nam ولی با حروف بزرگ می باشد.
در زمان ساخت ایندکس FUNCTION BASED تمام مقدارهای یک عبارت SQL محاسبه می گردند و به عنوان ایندکس ذخیره می شوند. این عبارت SQL می تواند شامل یک یا چند ستون از جدول باشد که روی آنها توابع SQL، توابع PL/SQL یا عملگرهای محاسباتی اعمال شده است. بنابراین OPTIMIZER برای QUERYهایی که نیاز به مقدارهای نهایی این عبارت دارند از ایندکس FUNCTION BASED استفاده می کند.
نکته: توابعی که در عبارت ایندکس استفاده می شوند باید از نوع DETERMINISTIC باشند یعنی به ازای یک ورودی خاص همیشه نتیجه یکسان بدهند.
نکته: اگر دستورات یک تابع تغییر یابد و مجدد کامپایل شود باید تمام ایندکس های FUNCTION BASED وابسته به آن را rebuild کرد در غیر این صورت نتایج توابع قبلی گزارش می شوند.
نکته: ایندکس های FUNCTION BASED می توانند با ساختمان داده BITMAP یا B-TREE تعریف شوند.
نکته: می توان ایندکس های FUNCTION BASED را به صورت ترکیبی و برای بیش از یک ستون تعریف نمود:
CREATE INDEX Compare_indexON Weatherdata_tab ((Maxtemp – Mintemp) DESC, Maxtemp);
نکته: نوع داده در عبارت ایندکس نمی تواند VARCHAR2 ، RAW ، LONGAW یا نوع داده ای که با طول نا مشخص است باشد. ولی اگر طول داده، مشخص باشد می توان از این نوع ایندکس ها استفاده نمود:
CREATE OR REPLACE FUNCTION initials (name IN VARCHAR2)
RETURN VARCHAR2 DETERMINISTIC IS BEGIN RETURN(‘A. J.’);
END;
/
/* Invoke SUBSTR both when creating index and when referencing function in queries. */
CREATE INDEX func_substr_index ON EMPLOYEES(SUBSTR(initials(FIRST_NAME),1,10));
SELECT SUBSTR(initials(FIRST_NAME),1,10) FROM EMPLOYEES
مزایای ایندکس های FUNCTION BASED
-باعث می شود دیتابیس بجای FULL TABLE SCAN از ایندکس استفاده کند تا performance بهبود یابد.
-از آنجایی که مقدار عبارتها از قبل محاسبه و ذخیره شده اند دسترسی به آنها با سرعت بیشتری انجام می شود.
معایب ایندکس هایFUNCTION BASED
– اگر عملیات DML برای ستون های عبارت ایندکس زیاد باشد استفاده از ایندکس های FUNCTION BASED از لحاظ performance به صرفه نخواهد بود.
– در عبارت ایندکس نمی توان از توابع گروهی (min,max,avg,…) استفاده نمود.
مقایسه COST ایندکس های متفاوت:
در متن ایندکس های BITMAP در دیتابیس اوراکل یک مثال برای بررسی کارایی ایندکس های BITMAP ارائه شد. در آن مثال، جدول KARBARAN با دو ستون ایجاد شد و یک میلیون مقدار تصادفی برای آن جدول تولید و درج گردید. در ادامه از همان جدول KARBARAN استفاده می گردد و COST اجرای QUERY زیر مقایسه می شود:
select count(*) from milad.karbaran t where upper(t.jens)=’MARD’;
حالت 1: بدون ایندکس
SQL> explain plan for select count(*) from milad.karbaran t where upper(t.jens)=’MARD’;
Explained
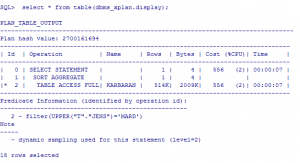
حالت 2: برای ستون jens ایندکس BITMAP تعریف می شود.
SQL> create bitmap index jens_bitmapind on milad.karbaran(jens);
Index created
SQL> explain plan for select count(*) from milad.karbaran t where upper(t.jens)=’MARD’;
Explained
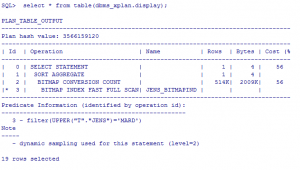
حالت 3: ایندکس B-TREE از نوع FUNCTION BASED تعریف می شود.
SQL> drop index jens_bitmapind;
Index dropped
SQL> create index jens_btreeFUNCTIONbased on milad.karbaran(upper(jens));
Index created
SQL> explain plan for select count(*) from milad.karbaran t where upper(t.jens)=’MARD’;
Explained
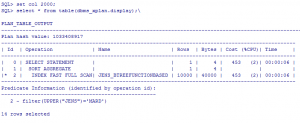
حالت 4: ایندکس BITMAP از نوع FUNCTION BASED تعریف می شود:
SQL> drop index JENS_btreeFUNCTIONbased;
Index dropped
SQL> create bitmap index jens_bitmapFUNCbased on milad.karbaran(upper(jens));
Index created
SQL> explain plan for select count(*) from milad.karbaran t where upper(t.jens)=’MARD’;
Explained
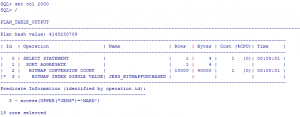
عالی. یک مشکل این ایندکس ها این هست که نمیشه جدولی که این ایندکس رو داره shrink کرد