ایندکس ترکیبی یا COMPOSITE INDEX برای دو یا چند ستون از جدول تعریف می شود ولی به هر ترتیبی که ستون ها در عبارت ساخت ایندکس قرار گیرند فقط یکسری از QUERYها می توانند از آن ایندکس استفاده کنند. در این متن روش استفاده مناسب از ایندکس های ترکیبی و نحوه عملکرد آنها را توضیح می دهیم.
همانطور که در مطلب ایندکس BITMAP در اوراکل اشاره شد اگر در یک جدول دو یا چند ستون دارای ایندکس BITMAP باشند در زمان اجرای QUERYهایی که شامل آن ستون ها هستند OPTIMIZER می تواند به صورت اتوماتیک ساختمان داده BITMAPها را به هم متصل کند و بین آنها عملیات منطقی بیتی انجام دهد. بنابراین زمانی که از ایندکس های BITMAP استفاده می شود نیاز نیست برای آن ستونها ایندکس های ترکیبی تعریف گردد.
انتخاب ترتیب ستون ها در زمان ساخت ایندکس ترکیبی از اهمیت زیادی برخوردار است. فرض کنید یک ایندکس ترکیبی برای ستون A ، B ، C و D از جدول testtbl با ترتیب (A,B,D,C) تعریف می شود:
Create index comp_abdc on testtbl(A,B,D,C);
با این ترتیب برای ستونها، QUERYهای زیر می توانند به نحو مطلوب از این ایندکس استفاده کنند:
-QUERYهایی که مقدارهای ستون A را بررسی می کنند
-QUERYهایی که مقدارهای ستون A و B را بررسی می کنند.
-QUERYهایی که مقدارهای ستون A و B و D را بررسی می کنند.
-QUERYهایی که مقدارهای هر چهار ستون را بررسی می کنند.
اوراکل برای دستیابی به مقدارهای نهایی در ایندکس های ترکیبی از KEY هایی استفاده می کند که براساس ترتیب ستون های آن ایندکس تشکیل می شوند. بنابراین QUERYهایی که نمی توانند از ترتیب صحیح برای KEY استفاده کنند از این ایندکس استفاده نخواهند کرد. (مانند یک QUERY که فقط مقدار سطرهای C و D را بررسی می کند)
نکته: ترتیب استفاده از ستون ها در QUERYها می تواند متفاوت از ترتیب ستون ها در ایندکس ترکیبی باشد. برای مثال دو QUERY زیر هیچ تفاوتی از لحاظ استفاده از ایندکس ترکیبی بالا ندارند:
Select * from testtbl where a > 5000 and d < 10 and b = 4
Select * from testtbl where b = 4 and d < 10 and a=234
نکته: بدلیل تفاوت در ترتیب ستون ها، می توان ایندکسهای ترکیبی زیر را برای جدول testtbl ساخت که هر کدام از آنها QUERYهای متفاوتی را پاسخ می دهند. البته تعریف همزمان این چند ایندکس ترکیبی باعث سربار در عملیات DML و افزایش فضای مصرفی می شود:
CREATE INDEX comp_abcd ON testtbl(a,b,c,d);
CREATE INDEX comp_adc ON testtbl (a,d,c);
CREATE INDEX comp_abdc ON testtbl (b,d,a,c);
استفاده مناسب از ایندکس ترکیبی بجای ایندکس های مجزا می تواند باعث بهبود PERFORMANCE شود.
چه زمانی از ایندکس های ترکیبی استفاده می شود؟
QUERYهای زیر را در نظر بگیرید:
1) Select count(*) from tbl where a > 5000 and c = ‘T’ and b = ‘F’
2) Select count(*) from tbl where c = ‘F’
ایندکس های زیر تعریف می شوند:
Create index ind_a on tbl(a);
Create index ind_c on tbl(c);
OPTIMIZER برای QUERY شماره 1 می تواند از ایندکس ind_a یا ind_c استفاده کند. فرض کنید از ایندکس ind_a استفاده می کند. در این حالت OPTIMIZER برای ستون های دیگر شرایط آنها در عبارت WHERE یعنی c = ‘F’ و b = ‘T’ را بررسی می کند و عمل فیلتر (FILTER) را انجام می دهد تا به سطرهای نهایی دست یابد.
نکته: اگر در جدول tbl برای یکی از سطرهای a، b یا c ایندکس عادی تعریف شده باشد OPTIMIZER برای QUERY شماره 1 می تواند از هر کدام از این ایندکس ها به عنوان تنها مسیر دسترسی برای دستیابی به سطرهای نهایی استفاده کند. ( OPTIMIZER برای بررسی شرایط قسمت WHERE در QUERY شماره 1 فقط از یک ایندکس استفاده می کند.)
QUERY شماره 2 نیز با استفاده از ایندکس ind_c به سطرهای مورد نطر می رسد.
در ادامه بجای ایندکس های بالا ایندکس ترکیبی برای سه سطر a ، b و c تعریف می شود:
Drop index ind_a;
Drop index ind_c;
Create index comp_abc on tbl(a,b,c);
OPTIMEZER می تواند با پیمایش ایندکس ترکیبی با سرعت بیشتر نسبت به زمانی که از ind_a یا ind_c استفاده می کرد به نتایج QUERY شماره 1 برسد زیرا در پیمایش این ایندکس از KEYهای هر سه ستون برای دسترسی به مقدار نهایی استفاده می کند.
در این حالت QUERY شماره 2 نمی تواند از ایندکس ترکیبی استفاده کند و عمل FULL TABLE SCAN انجام می شود. زیرا ستون c در انتهای ایندکس قرار گرفته است.
ولی اگر ایندکس ترکیبی با ترتیب (c,a,b) تعریف شود هر دو QUERY از این ایندکس استفاده می کنند:
Drop index comp_abc;
Create index comp_cab on tbl(c,a,b);
بنابراین استفاده مناسب از ایندکس ترکیبی می تواند سبب بهبود PERFORMANCE در اجرای QUERYها شود.
تعریف ایندکس ترکیبی به صورت بهینه
برای اینکه OPTIMIZER بتواند از ایندکس های ترکیبی به نحو مطلوب استفاده کند بهتر است تعداد و ترتیب ستون ها را براساس QUERYهایی که بیشتر اجرا می شوند انتخاب کرد ولی رعایت موارد زیر نیز توصیه می گردد:
– پیشنهاد می شود ستون اول در ایندکس ترکیبی، UNIQUE یا نزدیک به UNIQUE باشد. زیرا با توجه به ساختمان داده B-TREE اگر اولین ستون ایندکس، UNIQUE باشد برای پیدا کردن نتیجه QUERY بخش زیادی از آن ایندکس پیمایش می شود.
– توصیه می گردد ستونهایی که در QUERYها برای آنها از عملگر تساوی ‘=’ استفاده می شود به عنوان اولین ستون تعریف شوند و ستون هایی که دارای عملگر های شرطی ( > ، < ، =< ، BETWEEN) هستند به عنوان ستون های بعدی قرار بگیرند.
– بهتر است ستون هایی که بیشتر در قسمت SELECT یا در قسمت ORDER BY هستند آخر از همه ستون ها قرار گیرند.
– استفاده از حداکثر 3 ستون در ساخت ایندکس ترکبیی می تواند سبب بهبود PERFORMANCE شود.
معایب ایندکس ترکیبی:
-در تعریف ایندکس ترکیبی ترتیب ستونهای آن سبب نتایج متفاوت در سرعت اجرای QUERYها می شود.
-استفاده از تعداد ستون های زیاد سبب افزایش فضای دیسک و حافظه مورد نیاز می شود.
-افزایش تعداد ایندکس های ترکیبی می تواند موجب overhead در عملیات DML شود.
SKIP SCAN در ایندکس های ترکیبی
گاهی اوقات اگر ستون اول در ایندکس ترکیبی دارای cardinality خیلی کم باشد OPTIMIZER می تواند برای QUERYهایی که در آنها از ستون اول استفاده نشده است آن ستون را نادیده بگیرد و از ایندکس ترکیبی استفاده کند. این عمل را SKIP SCAN می نامند.
زمانی که ستون اول ایندکس ترکیبی تعداد بسیار کمی از مقدارهای DISTINCT دارد این عمل از لحاظ PERFORMANCE به صرفه خواهد بود.
فرض کنید برای جدول custumers ، ایندکس ترکیبی زیر تعریف می شود:
Create inex comp_ind on costumers(cust_gender,cust_email)
در این جدول،ستون cust_gender فقط دارای مقدارهای M و F برای مشخص کردن جنسیت افراد است.
بنابراین مقدارهای نهایی در ایندکس comp_ind به این شکل هستند:
F,Wolf@company.com,rowid
F,Wolsey@company.com,rowid
F,Wood@company.com,rowid
F,Woodman@company.com,rowid
F,Yang@company.com,rowid
F,Zimmerman@company.com,rowid
M,Abbassi@company.com,rowid
M,Abbey@company.com,rowid
QUERY زیر اجرا می شود:
SELECT * FROM customers WHERE cust_email = ‘Abbey@company.com’;
از آنجایی که تعداد مقدارهای DISTINCT در ستون اول فقط دو مورد است OPTIMIZER می تواند تعداد مسیرهای منطقی را مشخص کند و از عمل SKIP SCAN استفاده کند. در این حالت با استفاده از QUERY زیر از ایندکس ترکیبی استفاده می شود:
SELECT * FROM sh.customers WHERE cust_gender = ‘F’
AND cust_email = ‘Abbey@company.com’
UNION ALL
SELECT * FROM sh.customers WHERE cust_gender = ‘M’
AND cust_email = ‘Abbey@company.com’;
CONDITIONAL UNIQUENESS
می توان برای چند ستون از جدول با استفاده از ایندکس های ترکیبی، FUNCTION BASED و UNIQUE ، شرایط CONDITIONAL UNIQUENESS را برقرارکرد.
مثال:
create unique index “name_and_email” on user(name, email);
مثال:
SQL> create table demo_fbi (
col1 number
, col2 number
, col3 varchar2(30)
, created_date date
, active_flag char(1) default ‘Y’
check (active_flag in (‘Y’,’N’)));
Table created.
SQL> — Conditional unique index on multiple columns
SQL> create unique index demo_fbi_idx
on demo_fbi
(case when active_flag = ‘Y’ then
col1 else null end,
case when active_flag = ‘Y’ then
col2 else null end);
Index created.
SQL> — (1,1) for active row
SQL> insert into demo_fbi values
(1, 1, ‘TEST3′, sysdate,’Y’);
1 row created.
SQL> — (1,1) again for active row
SQL> insert into demo_fbi values
(1, 1, ‘TEST4′, sysdate,’Y’);
insert into demo_fbi values
*
ERROR at line 1:
ORA-00001: unique constraint (HR.DEMO_FBI_IDX)violated
بررسی ایندکس ترکیبی و عادی برای QUERYهای مختلف
Create table milad.testtbl (id number(7), sakhteman int, avg_sal number);
Table created
SQL>
SQL> Begin
For i in 1..1000000
Loop
Insert into milad.testtbl
values(i,round(dbms_random.value(400,800)) , round(dbms_random.value(5000,9000),2));
If mod(i, 100) = 0 then
Commit;
End if;
End loop;
End;
/
SQL> create index milad.comp_ind_id_skh_avg on milad.testtbl(id,sakhteman,avg_sal);
Index created
SQL>
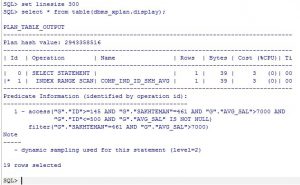
SQL> explain plan for select * from milad.testtbl g where g.id between 145 and 500 and g.sakhteman=461 and g.avg_sal > 7000;
Explained
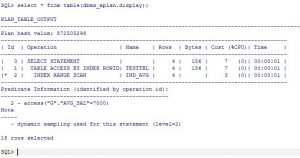
SQL> explain plan for select * from milad.testtbl g where g.avg_sal = 7000;
Explained
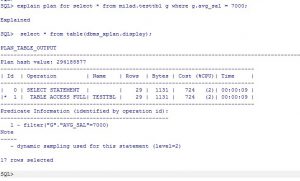
SQL> explain plan for select * from milad.testtbl g where g.sakhteman=461 and g.avg_sal > 7000;
Explained
SQL>
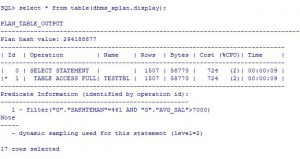
SQL> explain plan for select * from milad.testtbl g where g.id between 145 and 500;
Explained
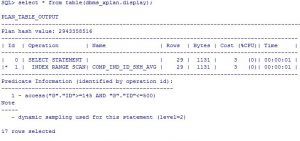
SQL> create index milad.ind_avg on milad.testtbl(avg_sal);
Index created
SQL> explain plan for select * from milad.testtbl g where g.avg_sal = 7000;
Explained
SQL>
عالی خیلی ممنون