در دیتابیس پستگرس، در زمان فراخوانی توابع به همراه دستور select الزامی به استفاده از کلمه کلیدی from نخواهد بود و انجام این کار، به اشکال زیر قابل انجام است:
شکل اول:
select function_name
شکل دوم:
Select * from function_name
شکل سوم:
select function_name from [table_name,view, …]
به طور مثال، برای اجرای تابع ()now که زمان جاری سیستم را برمی گرداند می توان به طروق زیر عمل کرد:
مثال 1:
postgres=# SELECT now();
now
——————————-
2020-03-30 00:51:10.952193-04
(1 row)
مثال 2:
postgres=# SELECT * FROM now();
now
——————————-
2020-03-30 00:54:32.453597-04
(1 row)
مثال 3:
postgres=# CREATE TABLE mytbl (id int);
CREATE TABLE
postgres=# SELECT now() from mytbl;
now
—–
(0 rows)
postgres=# insert into mytbl values(1);
INSERT 0 1
postgres=# SELECT now() from mytbl;
now
——————————-
2020-03-30 01:00:15.174394-04
(1 row)
در این حالت، خروجی تابع ()now به تعداد رکوردهای جدول mytbl تکرار خواهد شد:
postgres=# insert into mytbl values(2);
INSERT 0 1
postgres=# select count(*) from mytbl;
count
——-
2
postgres=# select now() from mytbl;
now
——————————-
2020-03-30 01:32:15.003273-04
2020-03-30 01:32:15.003273-04
(2 rows)
این مسئله برای توابع دیگر و حتی فراخونی nextval و currentval مربوط به seqeuenceها هم صادق می باشد. همچنین امکان اجرای چندین تابع در یک دستور select و انجام محاسبات و … هم وجود دارد:
postgres=# select SUBSTR(‘vahidusefzadeh’,6),now(),3+4-1,3*3;
substr | now | ?column? | ?column?
———–+——————————+———-+———-
usefzadeh | 2020-03-30 01:46:58.08913-04 | 6 | 9
(1 row)
برخلاف پستگرس، در دیتابیس اوراکل، فراخوانی توابع به همراه دستور select، اشکال مختلفی ندارد و صرفا به فرمت زیر می توان از توابع در دستور select استفاده کرد:
select function_name from {table_name,view_name,….}
مثال: تابع sysdate در اوراکل مشابه تابع ()now در پستگرس، زمان جاری سیستم را برمیگرداند. برای صدا زدن این تابع در اوراکل، می توانیم از جدول و ویوهای موجود در دیتابیس استفاده کنیم:
SQL> select sysdate from v$database;
SYSDATE
——————-
2020-03-30 01:22:07
توضیح: v$database یکی از ویوهای سیستمی اوراکل می باشد.
در صورتی که جدول یا ویوی مورد استفاده در دستور فوق، بیش از یک رکورد را دارا باشد، خروجی تابع sysdate هم به همان تعداد در خروجی تکرار خواهد شد:
SQL> select count(*) from v$datafile;
COUNT(*)
———-
4
SQL> select sysdate from v$datafile;
SYSDATE
——————-
2020-03-30 01:24:34
2020-03-30 01:24:34
2020-03-30 01:24:34
2020-03-30 01:24:34
در اوراکل هم امکان فراخوانی همزمان چندین تابع، انجام محاسبات ریاضی، برگرداندن یک رشته در خروجی و … صرفا در یک دستور select وجود دارد:
SQL> select sysdate,substr(‘vahidusefzadeh’,6) substr ,3+4-1,3*3,’jjjj’,1 from v$database;
SYSDATE SUBSTR 3+4-1 3*3 ‘JJJJ’ 1
———————— ————– ———- —— ——- —-
2020-03-30 01:54:25 usefzadeh 6 9 jjjj 1
همچنین در صورت استفاده از جداول فاقد محتوا، چیزی به عنوان خروجی برنمی گردد:
SQL> create table yyy as select * from mytbl where 1=2;
Table created.
SQL> truncate table yyy;
Table truncated.
SQL> select sysdate from yyy;
no rows selected
توضیحی در مورد جدول dual در اوراکل
معمولا عموم افرادی که با دیتابیس اوراکل کار می کنند، برای صدا زدن توابع سیستمی در دستور select، از جدول dual استفاده می کنند. این جدول توسط خود اوراکل ایجاد می شود و ساختار آن به صورت زیر می باشد:
SQL> desc dual;
Name Type
—————- ——————-
DUMMY VARCHAR2(1)
SQL> select * from dual;
DUM
—
X
همانطور که می بینید، جدول dual صرفا یک ستون دارد و خروجی دستور select بر روی این جدول هم مقدار X را برمی گرداند. البته این رکورد را می توان حذف کرد:
SQL> delete dual;
1 row deleted.
SQL> commit;
Commit complete.
SQL> select * from dual;
no rows selected
همچنین امکان اضافه کردن دیتا به این جدول هم وجود دارد:
SQL> insert into dual values(‘A’);
1 row created.
SQL> insert into dual values(‘B’);
1 row created.
SQL> commit;
Commit complete.
SQL> select * from dual;
DUM
—
A
SQL> select DUMMY from dual;
DUM
—
A
نکته جالبی که در خروجی دستور select فوق قابل مشاهده است، برگرداندن مقدار A از این جدول می باشد در صورتی که علاوه بر مقدار A، مقدار B هم به این جدول اضافه شده بود.
این جدول توسط همه کاربران قابل رویت می باشد این مسئله به ایجاد public synonymای که بر روی این جدول ایجاد شده است، برمیگردد:
SQL> select object_type,owner from dba_objects where object_name=’DUAL’;
OBJECT_TYPE OWNER
——————– ——————–
TABLE SYS
SYNONYM PUBLIC
سوال: چرا معمولا در هنگام عملیاتی چون صدا زدن توابع سیستمی، برگرداندن رشته و انجام محاسبات، از جدول dual استفاده می شود!؟
پاسخ کوتاه است، در صورت استفاده از جدول dual در دستور select هیچگونه i/o منطقی و فیزیکی رخ نخواهد داد و همچنین اجرای دستور برای توابع، رشته ها، محاسبات و … همیشه یک رکورد را برمی گرداند.
در صورتی که در مثالهای قسمت قبل مشاهده شد که اگر جدول فاقد رکورد باشد، مقدار sysdate در خروجی نمایش داده نمی شود و از طرفی دیگر، اگر جدول/ویو حاوی مقدار/مقادیر باشد نیاز است تا رکورد یا رکوردهای آن جدول از دیسک به حافظه منتقل شده و سپس عملیات مورد نظر در خروجی نمایش داده شوند که در این صورت، I/O ای رخ خواهد داد که عملا بدون دلیل بوده است. مثال زیر را ببینید.
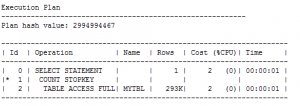
توجه: هنگام استفاده از جدول dual، در execution plan به جای FULL TABLE SCAN از عبارت FAST DUAL استفاده خواهد شد.
مثال: در این مثال، برای صدا زدن sysdate از جدول MYTBL استفاده شده است:
SQL> set timing on;
SQL> set autotrace traceonly
SQL> select sysdate from mytbl where rownum=1;
Elapsed: 00:00:00.05
Note
—–
– dynamic statistics used: dynamic sampling (level=2)
Statistics
———————————————————-
20 recursive calls
0 db block gets
187 consistent gets
300 physical reads
0 redo size
554 bytes sent via SQL*Net to client
402 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
3 sorts (memory)
0 sorts (disk)
1 rows processed
همانطور که از روی آمار می بینید، اطلاعاتی از جدول mytbl از دیسک به حافظه منتقل شده تا صرفا خروجی sysdate در حافظه دیده شود.
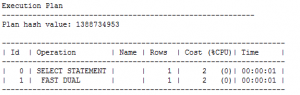
حال قصد داریم sysdate را با کمک جدول dual صدا بزنیم:
SQL> select sysdate from dual;
Elapsed: 00:00:00.01
Statistics
———————————————————-
1 recursive calls
0 db block gets
0 consistent gets
0 physical reads
0 redo size
554 bytes sent via SQL*Net to client
386 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
همانطور که می بینید، عملا I/O ای به لحاظ منطقی و فیزیکی برای اجرای این دستور اتفاق نیفتاده است.
حال حجم زیادی از دیتا را در جدول dual درج کرده و دستور قبلی را تکرار می کنیم:
SQL> insert into dual select 1 from dual connect by level<=500000;
500000 rows created.
SQL> commit;
Commit complete.
حجم جدول به 27 مگابایت رسیده است:
SQL> select bytes/1024/1024 SIZE_MB from dba_segments where segment_name=’DUAL’;
SIZE_MB
———-
27
اما اوراکل برای این جدول صرفا یک رکورد را برمی گرداند:
SQL> select count(*) from dual;
COUNT(*)
———-
1
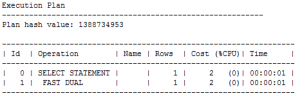
و آمار صدا زدن تابع sysdate هم مشابه قبل است:
SQL> set timing on;
SQL> set autotrace traceonly
SQL> select sysdate from dual;
Elapsed: 00:00:00.00
Statistics
———————————————————-
0 recursive calls
0 db block gets
0 consistent gets
0 physical reads
0 redo size
554 bytes sent via SQL*Net to client
386 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
rows processed
در چنین شرایطی با truncate کردن جدول dual هم عملا در خروجی و آمار دستور قبلی تغییری ایجاد نخواهد شد:
SQL> truncate table dual;
Table truncated.
SQL> select * from dual;
no rows selected
SQL> select sysdate from dual;
SYSDATE
——————-
2020-03-30 04:01:49
مقایسه ای پرفورمنسی بین جدول DUAL و non-DUAL
در پایان جدولی به نام mydual که ساختاری مشابه جدول dual دارد، را ایجاد کرده و با کمک یک بلاک plsqlای، جداول mydual و dual را به لحاظ پرفورمنسی مقایسه می کنیم.
SQL> create table mydual as select * from dual where 1=2;
Table created.
SQL> insert into mydual values(‘X’);
1 row created.
SQL> commit;
Commit complete.
اجرای بلاک plsqlای با کمک جدول mydual:
SQL> startup force;
SQL> set timing on
SQL> DECLARE
2 a varchar2(10);
3 BEGIN
4 FOR i IN 1 .. 9000000 LOOP
5 SELECT LOWER(‘USEF’) INTO a FROM mydual;
6 END LOOP;
7 END;
8 /
PL/SQL procedure successfully completed.
Elapsed: 00:02:37.56
همانطور که می بینید، این بلاک حدودا در دو دقیقه و سی وهفت ثانیه اجرا شده است.
حال همین بلاک plsqlای را با کمک جدول dual اجرا می کنیم:
SQL> startup force;
SQL> set timing on
SQL> DECLARE
2 a varchar2(10);
3 BEGIN
4 FOR i IN 1 .. 9000000 LOOP
5 SELECT LOWER(‘USEF’) INTO a FROM dual;
6 END LOOP;
7 END;
8 /
PL/SQL procedure successfully completed.
Elapsed: 00:00:55.27
همانطور که مشاهده می کنید، این بار بلاک plsqlای درکمتر از یک دقیقه (حدودا 57 ثانیه) اجرا شده و نسبت به اجرای قبلی، سرعت بسیار بالاتری داشته است.
Vahid Yousefzadeh
ارائه خدمات مشاوره ، پشتیبانی و نصب و راه اندازی پایگاه داده اوراکل در سراسر کشور...................... تلفن: 09128110897 ایمیل:vahidusefzadeh@gmail.com
عالی ، ممنون