در این متن قصد داریم به بررسی دو شیوه رایج انجام عملیات insert که Conventional و Direct-path(با کمک هینت append و append_values) می باشند، بپردازیم و در نهایت ویژگیها و چالشهای Direct-path insert را مورد بررسی قرار دهیم.
Conventional INSERT
در این روش، برای انجام عملیات insert در یک جدول، ابتدا جستجویی برای پیدا کردن بلاکهایی که قابلیت درج دارند(از بین بلاکهای فعلی جدول)، انجام خواهد شد و بعد از یافتن بلاکهای کاندید، اوراکل آنها را به حافظه منتقل می کند و نهایتا رکوردهای مورد نظر را در انها ثبت می کند.
در روش Conventional INSERT، جستجویی که قبل از درج انجام می شود، سبب خواهد شد تا در صورت وجود فضای خالی در جدول، از همان فضا برای درج رکوردهای جدید استفاده شود و به این جهت، فضای اضافه ای به جدول تخصیص داده نخواهد شد منتها بدیهی است که این جستجو می تواند سبب کندی(هر چند مختصر!) در زمان انجام عملیات insert شود.
پس در روش Conventional INSERT، اوراکل در ابتدا سعی می کند(در صورت امکان!)، از high water mark جدول تجاوز نکند که شکل زیر هم این مسئله را نشان می دهد:

***در صورت عدم آشنایی با مفهوم high water mark می توانید مطلب table reorganization را مطالعه بفرمایید.
در ادامه با ذکر دو مثال، بیشتر با شیوه Conventional INSERT آشنا خواهیم شد.
مثال اول: در ابتدا با کمک جدول $source جدولی با نام mytbl را ایجاد می کنیم که حجمی برابر با 37 مگابایت دارد:
SQL> create table mytbl as select * from sys.source$;
SQL> select bytes,blocks from dba_segments s where s.segment_name=’MYTBL’;
![]()
بعد از ایجاد جدول mytbl، همه رکوردهای این جدول را حذف می کنیم:
SQL> delete MYTBL;
همانطور که قابل انتظار هست، به دلیل استفاده از دستور delete، فضایی از این جدول آزاد نخواهد شد(به tablespace برنمی گردد):
![]()
مجددا همان اطلاعات را در جدول mytbl درج می کنیم:
SQL> insert into mytbl select * from sys.source$;
![]()
همانطور که می بینید، حجم جدول بدون تغییر مانده است و در زمان درج رکورد، از بلاکهای خالی جدول استفاده شده است.
مثال دوم: در مثال دوم هم با روشی دیگر، مجددا خواهیم دید که در حالت conventional path، از بلاکهای خالی و نیمه خالی برای ثبت رکوردهای جدید استفاده خواهد شد:
SQL> create table mytbl2 (test number);
SQL> insert into mytbl2 values(1);
SQL> insert into mytbl2 values(1);
SQL> commit;
بلاکی که برای رکورد فعلی استفاده شده است را با دستور زیر خواهید دید:
SQL> select dbms_rowid.rowid_relative_fno(rowid) as file#, dbms_rowid.rowid_block_number(rowid) as block# from mytbl2;
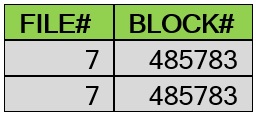
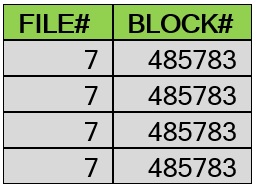
با درج رکوردهای بعدی، خواهیم دید که کماکان از همان بلاک 485783 استفاده می شود:
SQL> insert into mytbl2 values(1);
SQL> insert into mytbl2 values(1);
Direct-path INSERT
در مقابل Conventional INSERT، روش دیگری هم برای ثبت اطلاعات وجود دارد که Direct-path INSERT نام دارد در شیوه Direct-path INSERT، جستجویی برای یافتن بلاکهای خالی و یا نیمه خالی در جدول انجام نخواهد شد و برای انجام عملیات insert از بلاکهای جدیدی که در بالای high water mark قرار دارند، استفاده خواهد شد و در نتیجه، به حجم مصرفی جدول هم اضافه می شود!
منتها در صورتی که قصد داریم حجم قابل توجهی از اطلاعات را در جدول ثبت کنیم، به دلیل عدم جستجو در یافتن بلاکهای کاندید، بر سرعت انجام عملیات insert هم اضافه خواهد شد مضاف بر آن، در این روش از درج اطلاعات، از buffer cache هم صرف نظر خواهد شد و به صورت مستقیم اطلاعات در دیسک نوشته خواهد شد که این مسئله هم می تواند بر سرعت درج انبوه اطلاعات بیفزاید.
در شکل زیر خواهیم دید که در زمان انجام عملیات insert در روش Direct-path، از فضای خالی جدول استفاده نخواهد شد و برای انجام ثبت اطلاعات، بلاکهای جدیدی را به جدول تخصیص خواهد داد:

نکته: برای درج اطلاعات به شیوه Direct-path، در صورت استفاده از عبارت values در دستور insert، باید از هینت APPEND_VALUES استفاده شود و در صورت استفاده از subquery، باید از هینت APPEND برای درج به روش Direct استفاده کرد.
در ادامه با ذکر دو مثال، بیشتر با شیوه INSERT Direct-path آشنا خواهیم شد.
مثال اول: در این مثال خواهیم دید که برخلاف روش conventional، در روش Direct-path از بلاکهای خالی و نیمه خالی(بلاکهای کاندید insert) برای عملیات insert استفاده نخواهد شد:
SQL> create table mytbl5 as select * from sys.source$;
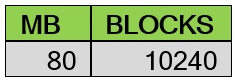
SQL> select bytes/1024/1024 MB,blocks from dba_segments s where s.segment_name=’MYTBL5′;
![]()
با دستور Delete اطلاعات جدول را حذف می کنیم(تغییری در HWM ایجاد نخواهد شد):
SQL> delete MYTBL5;
SQL> commit;
با دستور زیر، مجددا همان اطلاعات را در جدول mytbl5 درج می کنیم:
SQL> insert /*+APPEND*/ into mytbl5 select * from sys.source$;
SQL> commit;
خواهیم دید که فضای مصرفی جدول دوبرابر شده است:
مثال دوم: در این مثال هم مطلب مذکور به بیان دیگر آورده شده است:
SQL> create table mytbl3 (id number);
SQL> insert into mytbl3 values(1);
SQL> commit;
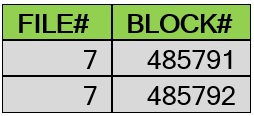
SQL> select dbms_rowid.rowid_relative_fno(rowid) as file#, dbms_rowid.rowid_block_number(rowid) as block# from mytbl3;
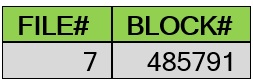
SQL> insert /*+APPEND_VALUES*/ into mytbl3 values(1);
SQL> commit;
SQL> insert /*+APPEND_VALUES*/ into mytbl3 values(1);
SQL> commit;
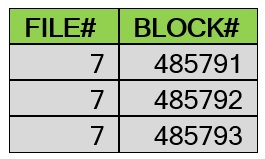
در این مثال مشاهده شد که برای درج سه رکورد، از سه بلاک مجزا استفاده شده است!
ویژگی ها و چالشهای درج به روش Direct-path
ویژگی اول: در زمان انجام عملیات Direct-path insert، از بافرکش صرف نظر می شود:
–conventional insert
SQL> select blocks from dba_segments where segment_name=’TB2‘;
4608
SQL> create table usef.tb as select * from usef.tb2 where 0=1;
Table created.
SQL> insert into usef.tb select * from usef.tb2;
279947 rows created.
SQL> select count(*) from v$bh where dirty=’Y’ and objd=(select object_id from dba_objects where object_name=’TB’);
COUNT(*)
———-
4608
–Direct-path insert
SQL> drop table usef.tb;
Table dropped.
SQL> create table usef.tb as select * from usef.tb2 where 0=1;
Table created.
SQL> insert /*+APPEND*/ into usef.tb select * from usef.tb2;
279947 rows created.
SQL> select count(*) from v$bh l where dirty=’Y’ and objd=(select l.object_id from dba_objects l where l.object_name=’TB’);
COUNT(*)
———-
80
ویژگی دوم: جدول در سطح exclusive قفل می شود.
در زمان درج اطلاعات در جدول به صورت Direct-path، جدول به صورت exclusive قفل خواهد شد و حتی امکان کمترین سطح از locking به session های دیگر داده نخواهد شد:
session 1:
SQL> select count(*) from mm;
COUNT(*)
———-
73652
SQL> insert /*+ APPEND */ into mytbl select * from sys.obj$;
73652 rows created.
با اجرای دستور insert توسط session 1، جدول mytbl در حالت exclusive قفل خواهد شد:
select p.SID,p.TYPE,p.LMODE,p.REQUEST,p.BLOCK from v$lock p where p.TYPE in (‘TX’,’TM’);

همانطور که می بینید، جدول در حالت (exclusive(LMODE=6، قفل شده است و کاربران دیگر امکان قفل کردن این جدول را در سطوح مختلف نخواهند داشت(البته تا زمانی که تکلیف این تراکنش مشخص شود):
–session 2
SQL> lock table mm in row share mode;
executing….
SQL> select obj# from mm where rownum<=1;
OBJ#
———-
16
SQL> delete mm where obj#=16;
executing….
با اجرای هر کدام از این در خواستها توسط session 2، این Session اصطلاحا block خواهد شد(block=1):
select p.SID,p.TYPE,p.LMODE,p.REQUEST,p.BLOCK from v$lock p where p.TYPE in (‘TX’,’TM’);
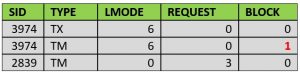
ویوی dba_blockers هم گواه این مسئله است:
select p.holding_session from dba_blockers p;

این اتفاق حتی در زمان استفاده از هینت append_values هم رخ خواهد داد.
**در صورت عدم آشنایی با ویوی v$lock می توانید مطلب Oracle Lock Management را مطالعه بفرمایید.
ویژگی سوم: عدم تولید redo در زمانی که جدول در حالت nologging باشد.
برای بررسی میزان اثرگذاری شیوه درج اطلاعات در redo generation، باید مسئله را در دو سطح archive log mode و noarchivelog mode بررسی کرد:
***no archive log mode***
SQL> create table myoldtbl as select * from mynewtbl where 1=2;
SQL> archive log list
Database log mode No Archive Mode
SQL> SET AUTOTRACE ON STATISTICS
SQL> insert into usef.myoldtbl select * from usef.mynewtbl;
589241 rows created.
Statistics
———————————————————-
642 recursive calls
79362 db block gets
14386 consistent gets
0 physical reads
80638780 redo size
871 bytes sent via SQL*Net to client
989 bytes received via SQL*Net from client
3 SQL*Net roundtrips to/from client
77 sorts (memory)
0 sorts (disk)
589241 rows processed
SQL> truncate table usef.myoldtbl;
Table truncated.
SQL> insert /*+APPEND*/ into usef.myoldtbl select * from usef.mynewtbl;
589241 rows created.
Statistics
———————————————————-
2529 recursive calls
12555 db block gets
13795 consistent gets
12 physical reads
232668 redo size
857 bytes sent via SQL*Net to client
1002 bytes received via SQL*Net from client
3 SQL*Net roundtrips to/from client
263 sorts (memory)
0 sorts (disk)
589241 rows processed
***no archive log mode + nologging***
SQL> alter table usef.myoldtbl nologging;
Table altered.
SQL> truncate table usef.myoldtbl;
Table truncated.
SQL> insert /*+APPEND*/ into usef.myoldtbl select * from usef.mynewtbl;
589241 rows created.
Statistics
———————————————————-
1477 recursive calls
12555 db block gets
12292 consistent gets
2 physical reads
230376 redo size
858 bytes sent via SQL*Net to client
1002 bytes received via SQL*Net from client
3 SQL*Net roundtrips to/from client
125 sorts (memory)
0 sorts (disk)
589241 rows processed
حال اگر دیتابیس در حالت archive log باشد:
***archive log mode***
SQL> archive log list
Database log mode Archive Mode
SQL> SET AUTOTRACE ON STATISTICS
SQL> insert into usef.myoldtbl select * from usef.mynewtbl;
589241 rows created.
Statistics
———————————————————-
544 recursive calls
79086 db block gets
14094 consistent gets
3 physical reads
80597820 redo size
873 bytes sent via SQL*Net to client
990 bytes received via SQL*Net from client
3 SQL*Net roundtrips to/from client
19 sorts (memory)
0 sorts (disk)
589241 rows processed
SQL> truncate table usef.myoldtbl;
Table truncated.
SQL> insert /*+APPEND*/ into usef.myoldtbl select * from usef.mynewtbl;
589241 rows created.
Statistics
———————————————————-
11916 recursive calls
12617 db block gets
31057 consistent gets
11 physical reads
81026692 redo size
860 bytes sent via SQL*Net to client
1002 bytes received via SQL*Net from client
3 SQL*Net roundtrips to/from client
1033 sorts (memory)
0 sorts (disk)
589241 rows processed
***archive log mode+nologging***
SQL> truncate table usef.myoldtbl;
Table truncated.
SQL> alter table usef.myoldtbl nologging;
Table altered.
SQL> insert /*+APPEND*/ into usef.myoldtbl select * from usef.mynewtbl;
589241 rows created.
Statistics
———————————————————-
11716 recursive calls
12557 db block gets
29856 consistent gets
2 physical reads
230124 redo size
860 bytes sent via SQL*Net to client
1003 bytes received via SQL*Net from client
3 SQL*Net roundtrips to/from client
846 sorts (memory)
0 sorts (disk)
589241 rows processed
اگر دیتابیس در حالت force logging قرار داشته باشد، nlogging بودن جدول اثری در redo size خواهد داشت؟
SQL> alter database force logging;
Database altered.
SQL> truncate table usef.myoldtbl;
Table truncated.
SQL> alter table usef.myoldtbl nologging;
Table altered.
SQL> insert /*+APPEND*/ into usef.myoldtbl select * from usef.mynewtbl;
589241 rows created.
Statistics
———————————————————-
12964 recursive calls
12584 db block gets
32446 consistent gets
7 physical reads
81006928 redo size
860 bytes sent via SQL*Net to client
1003 bytes received via SQL*Net from client
3 SQL*Net roundtrips to/from client
1284 sorts (memory)
0 sorts (disk)
589241 rows processed
همانطور که می بینیم، در صورتی که دیتابیس در حالت force logging باشد، از nologging در سطح جدول صرف نظر خواهد شد.
ویژگی چهارم: در هنگام استفاده از هینت append تولید undo به حداقل خواهد رسید:
*بررسی میزان undo تولید شده در حالت noappend:
SQL> startup force;
SQL> select used_ublk from v$transaction;
no rows selected
SQL> insert /*+noappend*/ into usef.mytable select * from usef.mytbl;
1399735 rows created.
SQL> select used_ublk from v$transaction;
USED_UBLK
———-
626
*بررسی میزان undo تولید شده در حالت append:
SQL> select used_ublk from v$transaction;
no rows selected
SQL> insert /*+APPEND*/ into usef.mytable select * from usef.mytbl;
1399735 rows created.
SQL> select used_ublk from v$transaction;
USED_UBLK
———-
2
ویژگی پنجم: زمان انجام rollback بسیار کاهش می یابد(در هنگام استفاده از Direct-path insert):
–noappend
SQL> set timing on
SQL> insert into usef.mytable select * from usef.mytbl;
5598940 rows created.
Elapsed: 00:02:01.58
SQL> rollback;
Rollback complete.
Elapsed: 00:01:14.22
–append
SQL> insert /*+APPEND */ into usef.mytable select * from usef.mytbl;
5598940 rows created.
Elapsed: 00:02:09.99
SQL> rollback;
Rollback complete.
Elapsed: 00:00:00.05
ویژگی ششم: در صورت انجام Direct-path insert در یک session، امکان اجرای پرس و جو بر روی جدول مورد نظر در آن session وجود ندارد مگر آنکه فرمان commit صادر شود:
SQL> insert /*+APPEND*/ into mytbl select * from oldtbl;
SQL> select * from mytbl;
ORA-12838: cannot read/modify an object after modifying it in parallel
SQL> commit;
SQL> select id from mytbl;
5
8
ویژگی هفتم: در صورت استفاده از referential integrity و یا trigger بر روی جدول مورد نظر، امکان انجام Direct-path insert وجود ندارد(استفاده از هینت APPEND تاثیری نخواهد داشت) مگر آنکه آنها را در وضیعت disable قرار دهیم:
SQL> create table parent_tbl(a number primary key,b number unique);
SQL> create table child_tbl(c number,b_fk ,CONSTRAINT fkkkk FOREIGN KEY (b_fk) REFERENCES parent_tbl(b) ON DELETE CASCADE);
SQL> insert into parent_tbl values(3,4);
SQL> insert into parent_tbl values(1,2);
SQL> commit;
SQL> insert /*+APPEND_VALUES*/ into child_tbl values(2,2);
قبل از انکه فرمان commit را صادر کنیم، در همین session از این جدول، گزارشی می گیریم با توجه به انکه هنوز commitای انجام نشده است، باید دستور select با خطا متوقف شود و اجرای درست دستور، به معنی عدم استفاده از هینت APPEND بوده است:
SQL> select count(*) from child_tbl;
2
با حذف کلید خارجی، مشکل مرتفع خواهد شد:
SQL> alter table CHILD_TBL drop constraint FKKKK;
SQL> insert /*+APPEND_VALUES*/ into child_tbl values(3,2);
SQL> select count(*) from child_tbl;
ORA-12838: cannot read/modify an object after modifying it in parallel
همچنین با ایجاد تریگر هم خواهیم دید که از هینت APPEND صرف نظر می شود:
SQL> alter table MYTABLE disable constraint SYS_C007492;
SQL> create or replace trigger mytrg
before insert on MYTABLE
for each row
begin
null;
end;
/
SQL> insert /*+APPEND*/ into mytable select * from nn;
SQL> select * from mytable;
2
9
همانطور که می بینید، به طور کلی از هینت APPEND استفاده نشده است حال تریگر را حذف کرده و دستور insert را تکرار می کنیم:
SQL> drop trigger mytrg;
SQL> insert /*+APPEND*/ into mytable select * from nn;
SQL> select * from mytable;
ORA-12838: cannot read/modify an object after modifying it in parallel
با حذف تریگر، از هینت APPEND استفاده خواهد شد.
ویژگی هشتم: زمانی که از Direct-path insert استفاده می شود، عبارت LOAD AS SELECT در plan دستور قابل مشاهده است:

همچنین در حالت conventional insert، عبارت LOAD TABLE CONVENTIONAL در plan دستور قابل مشاهده خواهد بود:
insert into tb select * from tb2;

ویژگی نهم: با فعالسازی همروندی در سطح session، عملیات insert به صورت Direct-path انجام خواهد شد مگر آنکه از هینت NOAPPEND استفاده شود:
SQL> ALTER SESSION FORCE PARALLEL DML;
Session altered.
SQL> insert into usef.mytable select * from usef.mytbl where rownum<=10;
10 rows created.
SQL> select count(*) from usef.mytable;
ORA-12838: cannot read/modify an object after modifying it in parallel
مقایسه کارایی Direct-path insert و conventional insert
استفاده نابجا از Direct-path insert می تواند سبب کندی اجرای دستور insert و همچنین افزایش بی مورد فضای مصرفی جدول شود و عمدتا این روش از insert، در محیط DW کاربرد دارد(به دلیل حجم بالای insert و (معمولا!) عدم نیاز به redo و undo و …) و استفاده بی حساب از این روش در محیط OLTP، می تواند سبب ایجاد locking و حتی کندی در سرعت عملیات insert شود.
برای مقایسه کارایی بین این دو روش، نیاز است ملاحظاتی را منظور داشت در غیر این صورت، این مقایسه چندان قابل ارزش نخواهد بود. برای مثال، زمانی کندی درج انبوه اطلاعات به روش conventional خودش را نشان می دهد که بلاکهای خالی و نیمه خالی(کاندید برای insert) در جدول به نسبت زیاد باشد. با این حال، مقایسه ای(هر چند ناقض!!) را در ادامه با هم خواهیم دید.
مثال: جدول mytbl حدودا 40 میلیون رکورد دارد:
SQL>select count(*) from mytbl;
38895648
سه جدول با ساختار جدول mytbl ایجاد می کنیم:
SQL>create table conven_tbl as select * from mytbl where 1=2;
SQL>create table direct_tbl as select * from mytbl where 1=2;
SQL>create table direct_nolog_tbl as select * from mytbl where 1=2;
جدول direct_nolog_tbl را در حالت nologging قرار می دهیم همچنین بانک هم در حالت force logging قرار ندارد:
SQL>alter database no force logging;
SQL>alter table direct_nolog_tbl nologging;
حال سرعت درج اطلاعات در این سه جدول را مقایسه می کنیم:
— conventional
SQL> startup force;
SQL> set timing on
SQL> insert into conven_tbl select * from mytbl;
38895648 rows created.
Elapsed: 00:03:43.96
–direct-path
SQL> startup force;
SQL> set timing on
SQL> insert /*+APPEND*/ into direct_tbl select * from mytbl;
38895648 rows created.
Elapsed: 00:02:21.81
–direct-path + nologging
SQL> startup force;
SQL> set timing on
SQL> insert /*+APPEND*/ into direct_nolog_tbl select * from mytbl;
38895648 rows created.
Elapsed: 00:02:01.90
همانطور که ملاحظه شد، درج اطلاعات در حالت nologging و همچنین direct path سرعت بالاتری را به همراه دارد البته ممکن است فضای بیشتری برای این روش از درج نیاز باشد:
SQL>select owner,segment_name,bytes/1024/1024 MB from dba_segments p where p.segment_name in (‘CONVEN_TBL’,’DIRECT_TBL’,’DIRECT_NOLOG_TBL’);

Vahid Yousefzadeh
ارائه خدمات مشاوره ، پشتیبانی و نصب و راه اندازی پایگاه داده اوراکل در سراسر کشور...................... تلفن: 09128110897 ایمیل:vahidusefzadeh@gmail.com
Comment (1)